
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
¿Por qué la variable tabla no usa paralelismo?
Las variables tablas tienen sus particularidades y siempre han sido de interesante estudio. Si bien su uso suele ser común en diferentes escenarios, es importante conocer sus limitaciones y desventajas. Ahora veremos por qué la variable tabla no usa paralelismo y cuál es el problema en este comportamiento.
Seguro que ya viste el artículo en el que comparamos las Variables tabla vs Tablas Temporales, esto te dará los conceptos iniciales para entender los principios.
Antes de empezar
Lo primero que debes hacer es Comprender el paralelismo en SQL Server. Con estos conceptos claros, podemos continuar aquí.
Si ya leíste el artículo que te comento en el párrafo anterior, podrás ver que no siempre hablar de paralelismo significa estar haciendo mejor las cosas. Hay casos en los que el paralelismo nos ayuda como otros casos en los que puede que no.
Creamos datos de prueba
¿Quieres seguir la demostración para entender mejor el ejemplo? Puedes empezar creando una tabla de prueba. Puedes usar las tradicionales bases de datos de ejemplo de Microsoft.
Yo en este caso me basaré en la creación de una tabla con millones de datos aleatorios que ya creamos anteriormente como puedes ver en el enlace. Utilizaré solo unos cuantos datos de allí.
Demostramos que la variable tabla no usa paralelismo
Muchos son los procesos que pueden llegar a utilizar procesamiento en paralelo. Veamos cúal es la reacción en este ejemplo cuando creamos una tabla temporal y una variable tabla con los mismos datos.
Voy a crear una tabla temporal con 100.000 registros provenientes de la tabla FakeTable (creada en el artículo antes referenciado). Lo mismo haremos con una variable tabla como puedes ver en el código.
-- Creamos la tabla temporal
CREATE TABLE #FakeTable(
[RowId] [int],
[Name] [varchar](16),
[MiddleName] [varchar](16),
[Office] [int],
[Gender] [smallint],
[DayOfBirth] [date],
[DescriptionText] [varchar](500)
)
INSERT INTO #FakeTable
SELECT TOP (100000) [RowId]
,[Name]
,[MiddleName]
,[Office]
,[Gender]
,[DayOfBirth]
,[DescriptionText]
FROM [dbo].[FakeTable]
-- Creamos la variable tabla
DECLARE @FakeTable TABLE (
[RowId] [int],
[Name] [varchar](16),
[MiddleName] [varchar](16),
[Office] [int],
[Gender] [smallint],
[DayOfBirth] [date],
[DescriptionText] [varchar](500)
)
INSERT INTO @FakeTable
SELECT TOP (100000) [RowId]
,[Name]
,[MiddleName]
,[Office]
,[Gender]
,[DayOfBirth]
,[DescriptionText]
FROM [dbo].[FakeTable]
-- Dos simples consultas
SELECT TOP 200 *
FROM #FakeTable
ORDER BY DayOfBirth DESC
SELECT TOP 200 *
FROM @FakeTable
ORDER BY DayOfBirth DESC¿Qué pasa al ejecutarlo?
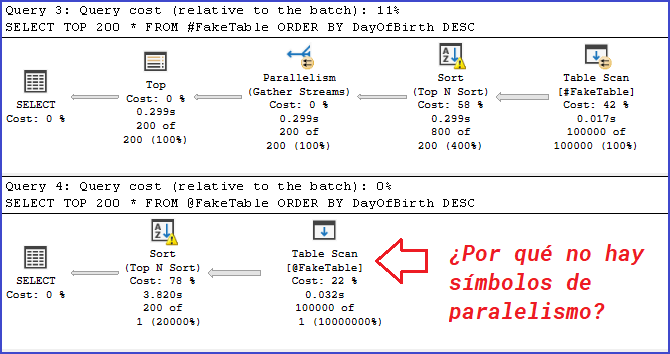
Bastante explícito. La variable tabla no tienen en ningún lugar señales de querer usar paralelismo.
Pero los datos en las tablas son idénticos, ¿verdad? No solo los datos, tamién las estructuras de las tablas y también la consulta es idéntica.
No sé si lo notaste, pero hay un pequeño gran detalle. Vuelve a mirar ambos planes de ejecución y mira las diferencias entre la cantidad de filas actuales y estimadas de ambos Table Scan.
He ahí un dato bastante importante a mirarlo. Voy a seleccionar el componente de la lectura de la variable tabla para que puedas ver mejor este detalle.
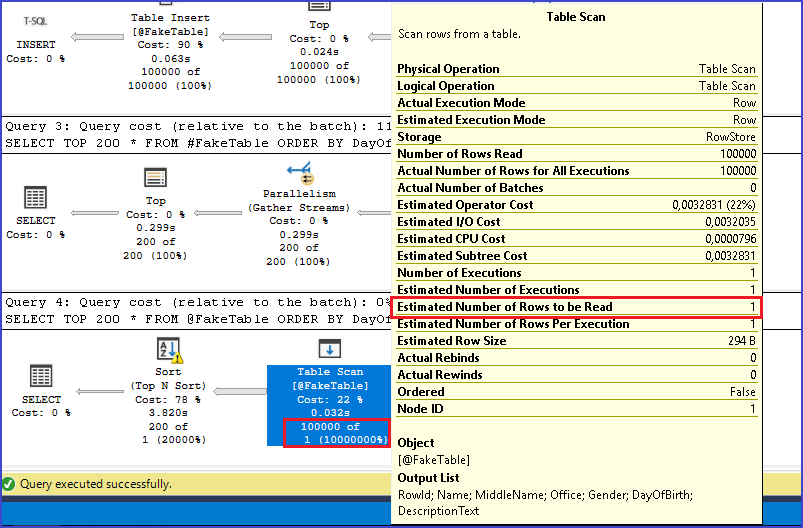
Fíjate bien. El número estimado de filas que va a retornar la lectura de registros de esta variable tabla es igual a 1. Esto quiere decir que SQL Server esperaría retornar 1 registro.
Tal vez te suene familiar que ya lo habíamos discutido en el artículo Problemas con el tipo de dato table.
Aquí está el motivo, y suena bastante lógico. Si el motor asume que solo tiene que procesar una fila de una tabla, ¿cuál sería la necesidad de usar paralelismo?
La variable table no usa paralelismo
Como puedes ver, acá también tienes un punto que evaluar cuando estás haciendo revisión del rendimiento.
Si bien, dependiendo de la versión de SQL Server que tengas, esta estimación de filas puede ser de 1 o 100 registros, esto puede afectarte si tienes muchos más registros en una variable tabla.
Dentro de las novedades que te presenta SQL Server 2019 también está uno importante para este caso. Puedes ver cómo Mejorar las Variables Tabla con Table Deferred Compilation y analizar las nuevas alternativas.
Related Posts

