
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Comprender el paralelismo en SQL Server
Tareas en paralelo, distribución de carga en hilos, múltiples procesadores. Existen diferentes términos con los que podemos referenciar la palabra paralelismo en diseño de software. Ahora bien, veamos cómo es que debemos comprender el paralelismo en SQL Server. No es tan obvia la respuesta como usualmente se piensa.
Tareas en paralelo
Mientras más trabajo es mejor distribuir la carga ¿verdad?
Imaginemos un proyecto de desarrollo de software que consta de 50 módulos. ¿Usualmente a cuántos programadores se designa la tarea? Si nos vamos al principio de que más manos harán más rápida la labor, pensamos en distribuir los módulos a más personas.
Evidentemente si asignamos 50 developers para esta tarea, cada uno trabajará con un módulo y es claro que el tiempo de trabajo será menor por cada uno. Obviamente comparando este escenario con una distribución a 5 developers que hagan a 10 módulos por cada uno.
Estoy seguro que mientras lees este artículo puedes pensar diferentes cosas respecto a lo que estamos hablando. También es parte de su objetivo.
Pensando en la idea de distribución a más personas para ahorrar tiempo, lo que debes pensar en el momento en el que cada developer termina su trabajo, es en la integración. Debe haber un encargado de la integración de los 50 resultados.
Ahora bien, ¿qué tan fácil sería integrar 50 módulos? ¿será más fácil integrar solo 10?
Paralelismo en SQL Server
La idea de trabajar con paralelismo en SQL Server tiene mucho que ver con la analogía planteada en líneas más arriba.
Tenemos en la arquitectura de SQL Server un encargado de distribuir la carga operativa y de entregar los resultados. Los «developers» en este caso son los worker threads, los encargados de hacer el trabajo en paralelo. El organizador o coordinador es a quien conocemos como thread 0.
Este en un claro ejemplo en el que el mismo query puede ser resuelto con diferentes interpretaciones en el plan de ejecución.
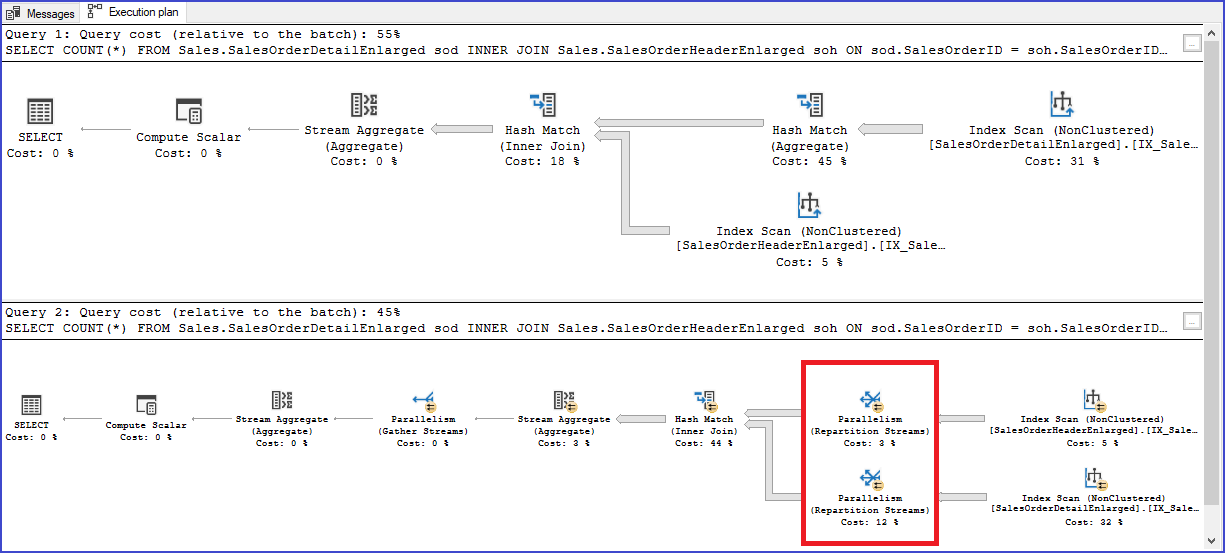
El paralelismo también tiene una afectación en los tiempos de espera. Se genera el conocido CXPacket y puedes ver el detalle acá. Esto no quiere decir que CXPacket sea del todo malo, pero es importante analizar sus dimensiones en nuestros servidores.
Conclusiones
- Lo que debemos medir en nuestro trabajo dentro del análisis de paralelismo es si una consulta es mejor o peor cuando se ejecuta en paralelo.
- Medir la afectación es muy importante
- No debemos considerar como un hecho que trabajar en múltiples threads es la mejor opción
- SQL Server decide cuándo utilizar paralelismo, esto se basa en configuraciones de la instancia y en los costos estimados de las consultas.
- Nuestro próximo paso será Identificar el paralelismo en SQL Server
Related Posts

