
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Eligiendo arquitecturas en Synapse Analytics
Uno de los principales objetivos de Azure en plantear diferentes arquitecturas en Synapse Analytics, es el tener esa posibilidad de distribución del poder de cómputo entre múltiples nodos. Esto es posible gracias a este planteamiento en el que el cómputo está separado del storage donde están los datos.
Antes de empezar
Muy breve, pero muy importante.
Si no has visto el artículo ¿Qué es Azure Synapse Analytics?, te recomiendo ir por allí primero.
Uno de los conceptos más relevantes sobre Synapse: Está diseñado sobre tecnología MPP (Massively Parallel Processing).
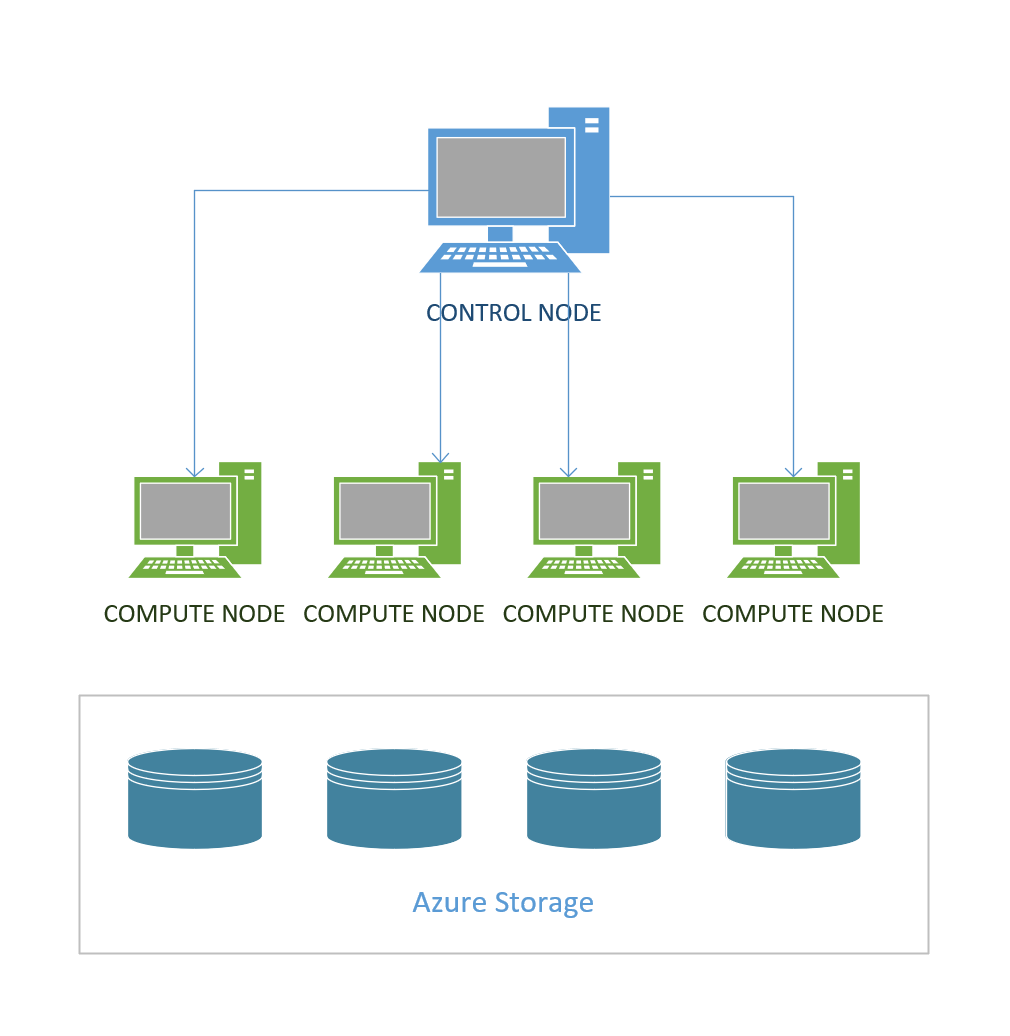
Componentes de la Arquitectura en Synapse Analytics
SI hay algo que permite este procesamiento en paralelo, es justamente esta separación de componentes.
Estos componentes son:
- Azure Storage
- Control Node
- Compute Node
Algunas consideraciones sobre estos componentes
Si los datos están en un Azure Storage, el cobro de almacenamiento va también por ese lado.
El Control Node es el encargado de recibir las consultas y de distribuir su procesamiento entre los Compute Nodes para aprovechar ese paralelismo.
La cantidad de Compute Nodes depende del nivel de servicio que se está adquiriendo en Synapse. También tiene que ver con el tipo de arquitectura que se usará (este detalle viene en un post posterior).
Más de las arquitecturas en Synapse Analytics
Hay mucho de lo que se tiene que hablar. Vamos a hacerlo por partes.
Luego de entender esta primera parte, iremos a describir cómo se puede trabajar de mejor manera en el almacenamiento de la información. Nos tocará hablar de distribuciones de datos.
Related Posts
