
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Uniqueidentifier vs Identity en el diseño de tablas – Parte 2
Entre las cosas más importantes en la programación de TSQL siempre estará el rendimiento. Es por esto que cuando hablamos de la comparación del uniqueidentifier vs identity en el diseño de tablas, este será un factor muy importante en la decisión sobre cuál debemos utilizar.
Si no lo has hecho aún, primero mira lo que hemos mostrado en la Primera Parte de la publicación Uniqueidentifier vs Identity en el diseño de tablas para tener claro los conceptos y lo que ya ha sido evaluado.
Trabajando con más información
El ejemplo del primer artículo se basaba simplemente en el uso de 10 registros por cada tabla. Una utilizando el uniqueridentifier y la otra utilizando el identity.
Mucha diferencia entre ellas, no era evidente.
Ahora bien, ya viste también cómo generar Millones de Datos Aleatorios en SQL Server, uso la misma base del script para generar un millón de datos con identity y un millón con uniqueidentifier.
Aumentando la complejidad de las estructuras
Para acercarnos más a un escenario real voy a adicionar algunos índices en las tablas.
CREATE INDEX IX_IdOffice ON [FakeTable_with_Identity] (Office)
CREATE INDEX IX_UnOffice ON [FakeTable_with_Uniqueidentifier] (Office)
CREATE INDEX IX_IdName ON [FakeTable_with_Identity] (Name, MiddleName)
CREATE INDEX IX_UnName ON [FakeTable_with_Uniqueidentifier] (Name, MiddleName)
CREATE INDEX IX_IdBirth ON [FakeTable_with_Identity] (DayOfBirth)
CREATE INDEX IX_UnBirth ON [FakeTable_with_Uniqueidentifier] (DayOfBirth)Consultando las tablas
Quiero mostrarte qué sucede en consultas sencillas con diferentes propósitos. Tal como te decía en el artículo Cómo hacer Testing en SQL Server, algo muy importante en las métricas es Medir la Cantidad de Lectura y por supuesto analizar los planes de ejecución.
Veamos algunos casos.
1) Lectura completa de las tablas
Vamos por los primero 20000 registros.
SELECT TOP 20000 *
FROM [dbo].[FakeTable_with_Identity]
SELECT TOP 20000 *
FROM [dbo].[FakeTable_with_Uniqueidentifier]Una generación de planes iguales con una pequeña diferencia en el costo.
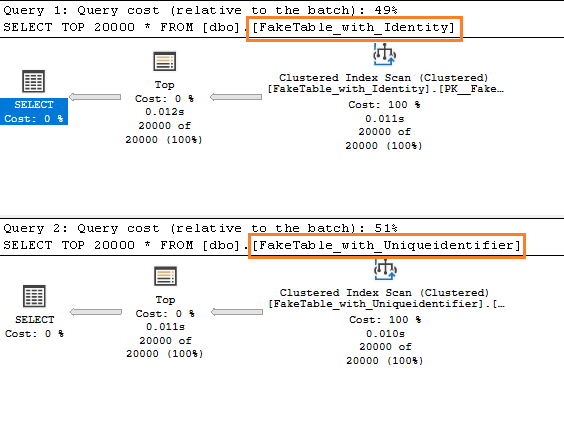
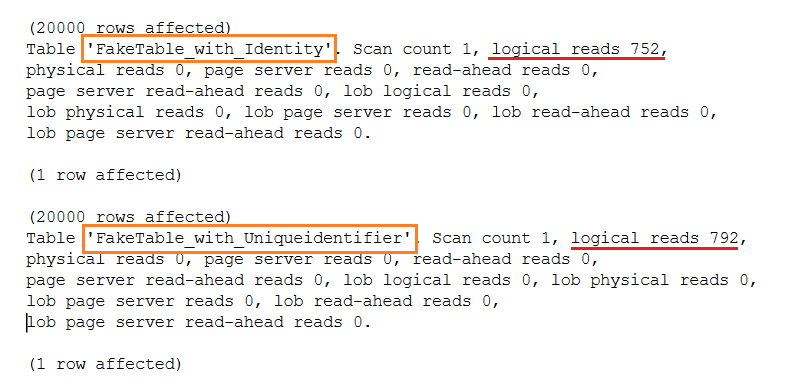
Y una similar sutil diferencia en la cantidad de páginas leídas
2) Algunas columnas con filtro y orden
SELECT Office, DayOfBirth, Name
FROM [dbo].[FakeTable_with_Identity]
WHERE Office = 136
ORDER BY RowId DESC
SELECT Office, DayOfBirth, Name
FROM [dbo].[FakeTable_with_Uniqueidentifier]
WHERE Office = 136
ORDER BY RowId DESCAhora con nuevos componentes pero bajo el mismo comportamiento y incluso los mismos costos.
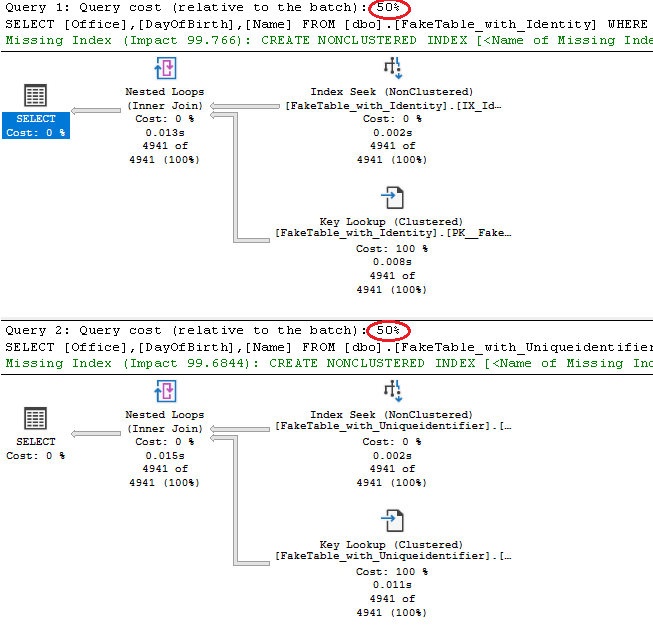
Adicionemos una tabla más
Para que podamos realizar JOINS crearé una tabla que simula ventas. Una por cada una de las tablas con las que ya he trabajado. La relación es muy intuitiva según las estructuras.
CREATE TABLE [dbo].[FakeSales_refIdentity](
[RowId] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY,
[Product] [int],
[Quantity] [int],
[Voucher] [int] NULL,
[EmployeeId] [int]
)
CREATE TABLE [dbo].[FakeSales_refUniqueidentifier](
[RowId] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY,
[Product] [int],
[Quantity] [int],
[Voucher] [int] NULL,
[EmployeeId] [uniqueidentifier]
)Es evidente que la prueba de relación se hará con el campo EmployeeId, ¿verdad?
Con el mismo esquema de llenar datos aleatorios, voy a poblar ambas tablas con 2.440.000 de registros cada una. Obviamente el campo de referencia para empleados contiene información que sí existe en las tablas previas.
Ahora bien, hora de la verdad. Vamos a hacer una consulta por cada tabla que las relacione. ¿Qué tal con algunos cálculos adicionales?
SELECT TOP 210
a.Name,
a.MiddleName,
b.Product,
b.Quantity,
COUNT(*) AS Total
FROM [FakeTable_with_Identity] a
INNER JOIN [FakeSales_refIdentity] b
ON a.RowId = b.EmployeeId
GROUP BY
a.Name,
a.MiddleName,
b.Product,
b.Quantity
ORDER BY 5 DESC
SELECT TOP 210
a.Name,
a.MiddleName,
b.Product,
b.Quantity,
COUNT(*) AS Total
FROM [FakeTable_with_Uniqueidentifier] a
INNER JOIN [FakeSales_refUniqueidentifier] b
ON a.RowId = b.EmployeeId
GROUP BY
a.Name,
a.MiddleName,
b.Product,
b.Quantity
ORDER BY 5 DESC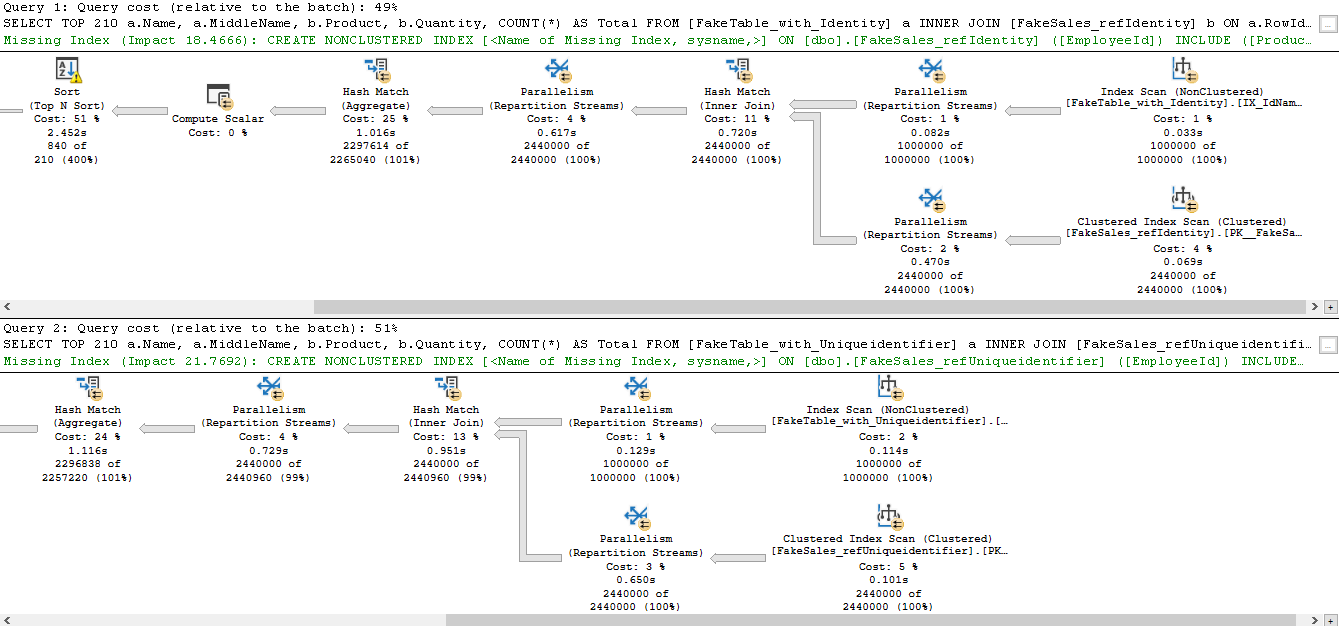
Los planes de ejecución nuevamente se ven bastante similares. Esto solamente significa que la forma de obtener la información será prácticamente idéntica en ambos casos.
Pero veamos las estadísticas de las consultas.

Ahora sí hay una clara diferencia. Incluso puede verse en el tiempo de ejecución que la segunda consulta ha tenido mayor duración.
Consideraciones del Uniqueidentifier e Identity en el diseño
Primero que nada, que no se nos olvide un concepto muy importante del diseño. No podemos obviar los tipos de datos en las tablas de SQL Server.
- Uniqueidentifier es un campo de 16 bytes
- Int es un campo de 4 bytes
Para empezar, la diferencia de tamaños en los tipos de datos te obligará a realizar mayor lectura en tus consultas.
Por supuesto, esto también impactará en tus necesidades de almacenamiento. Esto lo puedes ver al obtener el Reporte de Tablas de Bases de Datos donde verás información como esta a continuación.

Puedes evaluar int, smallint o bigint en función a tu necesidad. De todas maneras cualquiera termina siendo más pequeña que un uniqueidentifier.
Y hay más de lo que podemos hablar sobre este tema. ¿Qué pasa cuando evaluamos la concurrencia? Mira la Tercera Parte de esta serie.
Related Posts


Comments (2)
Los comentarios están cerrados.
Excelente documento apoyado por la demostración queda claro.
Gracias.
Gracias Civil Informatico, un gusto