
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Uniqueidentifier vs Identity en el diseño de tablas – Parte 3
Momento de ver las diferencias en inserciones de registros. Como ya vimos en los primeros artículos de esta serie, el diseño de tablas puede impactar tanto en almacenamiento como en rendimiento para tus sistemas. Ahora bien, vamos a la evaluación final de estos escenarios.
No olvides los previos
Primero, son importantes los conceptos. Si no lo has hecho aún, es un buen momento para ver la Primera Parte de la serie Uniqueidentifier vs Identity.
Continuando con la serie, hemos evaluado el rendimiento en lecturas más complejas y con millones de registros en una Segunda Parte.
Ahora bien, vamos a ver qué sucede cuando queremos adicionar nuevos registros a nuestra tabla.
Insertando filas en nuestras tablas
Voy a seguir utilizando las dos tablas con las que he trabajado en el artículo anterior. Las que tienen un millón de registros cada una.
Quiero ver cuál es la reacción cuando insertamos un par de registros en las tablas.
SET STATISTICS IO ON
INSERT INTO [dbo].[FakeTable_with_Identity]
([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES
(N'Monika', N'Tarah', 100, 5, CAST(N'2006-05-31' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu ele')
,(N'Grethel', N'Emalia', 193, 4, CAST(N'1967-09-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero')
,(N'Kandace', N'Suellen', 180, 4, CAST(N'1980-01-01' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, ')
,(N'Becki', N'Kimberly', 100, 2, CAST(N'1973-01-04' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdu')
,(N'Tonia', N'Stacey', 100, 4, CAST(N'2003-11-26' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu elementum felis tempor vel. Praesent tellus eros, rutrum ac facilisis quis, t')
,(N'Paulette', N'Demeter', 134, 5, CAST(N'1974-01-20' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id')
,(N'Olenka', N'Doretta', 100, 5, CAST(N'2009-04-11' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus ac')
,(N'Marlane', N'Janaye', 100, 2, CAST(N'1961-10-24' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a')
,(N'Shela', N'Fredi', 100, 5, CAST(N'1969-02-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse a')
,(N'Angela', N'Arluene', 200, 3, CAST(N'1987-11-03' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu elementum felis tempor vel. Praesent tellus eros, rutrum ac facilisis quis, ')
,(N'Monika', N'Tarah', 100, 5, CAST(N'2006-05-31' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit.')
,(N'Grethel', N'Emalia', 193, 4, CAST(N'1967-09-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing ')
,(N'Kandace', N'Suellen', 180, 4, CAST(N'1980-01-01' AS Date), N'Lorem ipsum ')
,(N'Becki', N'Kimberly', 100, 2, CAST(N'1973-01-04' AS Date), N'Lorem ipsum dolor sit amet, consecte')
,(N'Tonia', N'Stacey', 100, 4, CAST(N'2003-11-26' AS Date), N'Lorem ipsum dolor sit amet, co')
,(N'Paulette', N'Demeter', 134, 5, CAST(N'1974-01-20' AS Date), N'Lorem ipsum dolor sit amet, consectetur ad')
,(N'Olenka', N'Doretta', 100, 5, CAST(N'2009-04-11' AS Date), N'Lorem ipsum dolor sit am')
,(N'Marlane', N'Janaye', 100, 2, CAST(N'1961-10-24' AS Date), N'Lorem ipsum dolor si')
,(N'Shela', N'Fredi', 100, 5, CAST(N'1969-02-18' AS Date), N'Lorem ipsum dolor sit amet,')
,(N'Angela', N'Arluene', 200, 3, CAST(N'1987-11-03' AS Date), N'Lorem ipsu')
INSERT INTO [dbo].[FakeTable_with_Uniqueidentifier]
([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES
(N'Monika', N'Tarah', 100, 5, CAST(N'2006-05-31' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu ele')
,(N'Grethel', N'Emalia', 193, 4, CAST(N'1967-09-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero')
,(N'Kandace', N'Suellen', 180, 4, CAST(N'1980-01-01' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, ')
,(N'Becki', N'Kimberly', 100, 2, CAST(N'1973-01-04' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdu')
,(N'Tonia', N'Stacey', 100, 4, CAST(N'2003-11-26' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu elementum felis tempor vel. Praesent tellus eros, rutrum ac facilisis quis, t')
,(N'Paulette', N'Demeter', 134, 5, CAST(N'1974-01-20' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id')
,(N'Olenka', N'Doretta', 100, 5, CAST(N'2009-04-11' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus ac')
,(N'Marlane', N'Janaye', 100, 2, CAST(N'1961-10-24' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a')
,(N'Shela', N'Fredi', 100, 5, CAST(N'1969-02-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse a')
,(N'Angela', N'Arluene', 200, 3, CAST(N'1987-11-03' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius arcu purus, nec tristique elit pharetra ut. Vestibulum lobortis sagittis bibendum. Duis a libero interdum, faucibus dolor id, elementum purus. Fusce euismod fringilla libero. Suspendisse ac consectetur nisi, non scelerisque diam. Pellentesque ultrices dapibus accumsan. Phasellus cursus pulvinar mauris, eu elementum felis tempor vel. Praesent tellus eros, rutrum ac facilisis quis, ')
,(N'Monika', N'Tarah', 100, 5, CAST(N'2006-05-31' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing elit.')
,(N'Grethel', N'Emalia', 193, 4, CAST(N'1967-09-18' AS Date), N'Lorem ipsum dolor sit amet, consectetur adipiscing ')
,(N'Kandace', N'Suellen', 180, 4, CAST(N'1980-01-01' AS Date), N'Lorem ipsum ')
,(N'Becki', N'Kimberly', 100, 2, CAST(N'1973-01-04' AS Date), N'Lorem ipsum dolor sit amet, consecte')
,(N'Tonia', N'Stacey', 100, 4, CAST(N'2003-11-26' AS Date), N'Lorem ipsum dolor sit amet, co')
,(N'Paulette', N'Demeter', 134, 5, CAST(N'1974-01-20' AS Date), N'Lorem ipsum dolor sit amet, consectetur ad')
,(N'Olenka', N'Doretta', 100, 5, CAST(N'2009-04-11' AS Date), N'Lorem ipsum dolor sit am')
,(N'Marlane', N'Janaye', 100, 2, CAST(N'1961-10-24' AS Date), N'Lorem ipsum dolor si')
,(N'Shela', N'Fredi', 100, 5, CAST(N'1969-02-18' AS Date), N'Lorem ipsum dolor sit amet,')
,(N'Angela', N'Arluene', 200, 3, CAST(N'1987-11-03' AS Date), N'Lorem ipsu')
Como puedes ver, las estructuras son iguales a las que hemos visto hasta ahora.
¿Qué resultados podemos ver?
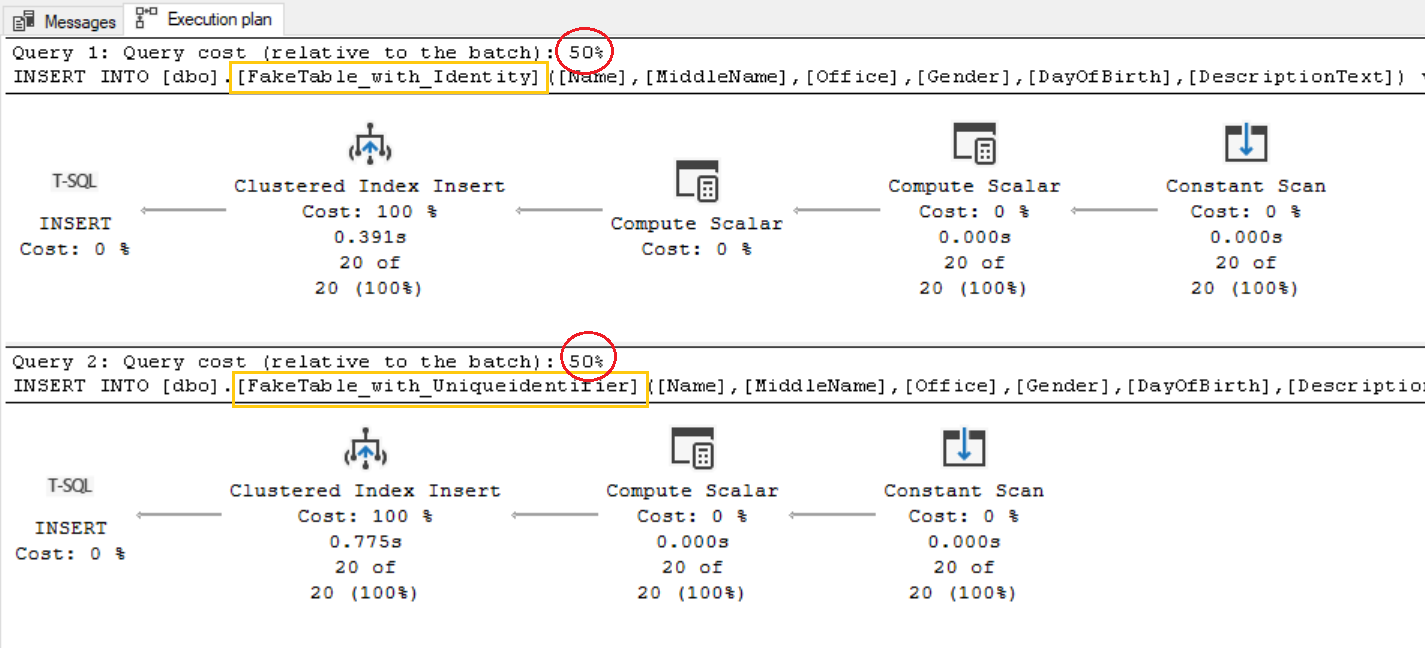
Si bien los planes de ejecución se ven muy similares a excepción de un componente, el costo parece ser el mismo para ambos casos.
¿Y qué dicen las estadísticas?
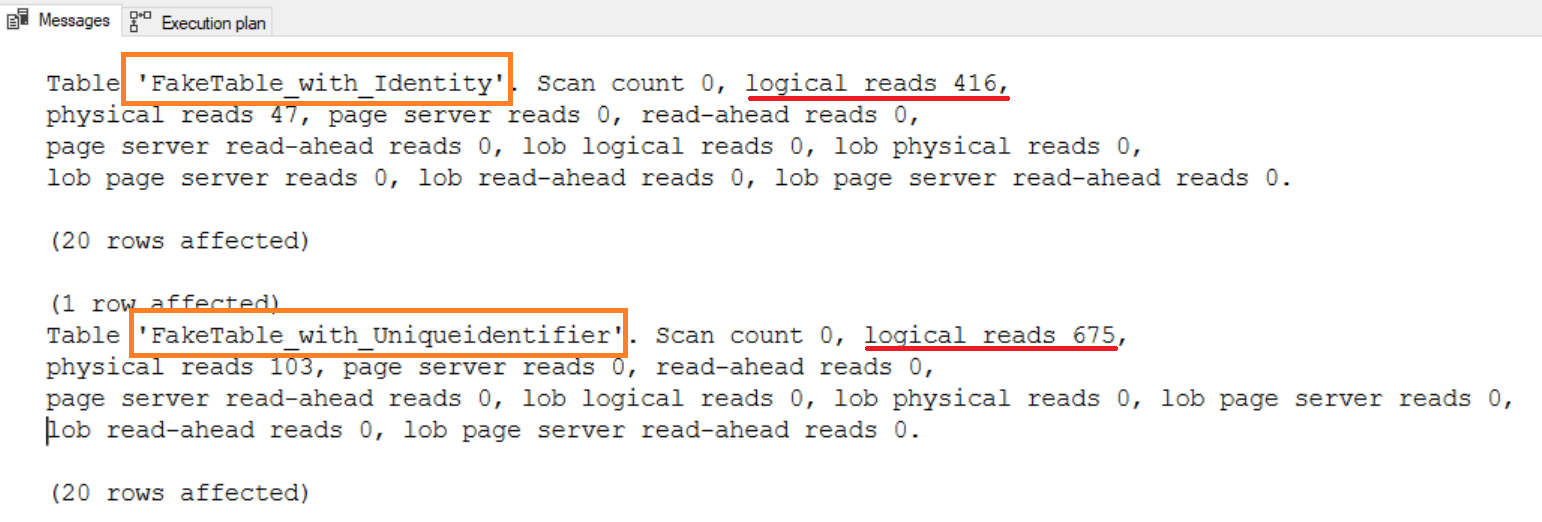
Aquí sí podemos ver una diferencia mayor. La inserción en la tabla cuyo identificador de la tabla es un número entero con valor identity, tiene una evidente menor cantidad de lectura que la tabla con el uniqueidentifier.
¿Qué pasa en concurrencia?
¿Qué tal si tienes varios usuarios en tu sistema tratando de hacer estas inserciones?
Veamos qué sucede cuando simulamos la acción de varios usuarios tal como lo explicamos en el artículo Pruebas de estrés en SQL Server con oStress. (Es importante que veas este artículo para comprender lo que hago en el paso siguiente).
Simularé 20 usuarios concurrentes y cada uno con un ciclo de 1000 inserciones una a una. Las sentencias de la línea de comandos para oStress serían así:
ostress.exe -S.\sql19 -dBigTables -Q”INSERT INTO [dbo].[FakeTable_with_Identity] ([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES (N’Kandace’, N’Suellen’, 180, 4, CAST(N’1980-01-01′ AS Date), N’Lorem ipsum ‘)” -n20 -r1000
ostress.exe -S.\sql19 -dBigTables -Q”INSERT INTO [dbo].[FakeTable_with_Uniqueidentifier] ([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES (N’Kandace’, N’Suellen’, 180, 4, CAST(N’1980-01-01′ AS Date), N’Lorem ipsum ‘)” -n20 -r1000
Los resultados aquí sí son mucho más interesantes.
INSERT en la tabla con IDENTITY

Ejecutado en 23 segundos.
INSERT en la tabla con UNIQUEIDENTIFIER

Ejecutado en 5 minutos y 47 segundos.
Diseño de tablas con Identity o Uniqueidentifier
Viste tremenda diferencia de tiempos en la inserción de datos con el ejemplo de la concurrencia.
Al principio de este artículo viste esa sutil diferencia en la cantidad de lectura que tienen los dos casos.
Esto también es impactado por el índice clustered que tenemos creado en cada una de las tablas. Por teoría sabemos que los registros insertados deben estar ordenados en función al campo llave que hemos escogido. Por supuesto, en este caso, tenemos una llave Uniqueidentifier y otra Identity. Esta teoría la encuentras en la documentación oficial.
Has la prueba en tus escenarios y toma en cuenta todo lo que hemos visto en esta serie de publicaciones.
Related Posts

