
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Uniqueidentifier vs Identity en el diseño de tablas
¿Cuál es la mejor manera de identificar registros de una tabla? Aquí es donde surge la pregunta que da el título de esta publicación. Uniqueidentifier vs Identity, ¿cuál es mejor y por qué? Veamos puntos importantes en esta discusión.
(Para no entrar en confusión, cada que me refiero a un «registro de una tabla» me estoy refiriendo a «una fila completa»)
Identificadores en una tabla
Ya sea que estás siguiendo los conceptos sobre normalización o aunque sea solamente de una manera intuitiva, necesitas identificar cada registro de tu tabla.
Lo que buscas es una columna con un valor único, obviamente lo que queremos es que nunca se repita.
¿Qué es Uniqueidentifier?
Para empezar es otro tipo de dato en SQL Server y también conocido como un GUID (Global Unique Identifier) de 16 bytes.
Estos valores GUID pueden ser generados utilizando las funciones NEWID o NEWSEQUENTIALID. Puedes tener más detalles y ejemplos en la documentación oficial.
Me detengo aquí un momento…
Si es un GUID, o sea, si es un valor que no se va a repetir nunca pues encaja perfectamente al concepto que estamos buscando sobre un valor identificador para cada registro de una tabla. ¿Verdad?
¿Podríamos usar un identificador del tipo Uniqueidentifier tal vez como Primary Key? Podría ser una opción.
¿Qué es Identity?
Es una propiedad de una columna dentro de una tabla. No es un tipo de dato como el caso anterior, sin embargo, puede ser aplicado a una columna.
Esta propiedad permite que cada registro en una tabla tenga un nuevo valor para la columna a la cual aplicas la propiedad.
Me detengo nuevamente…
Si cada fila de la tabla va a tener un valor nuevo en la columna seleccionada, también aplica al concepto que buscamos.
¿Qué resulta de un Uniqueidentifier vs Identity?
Crearé dos tablas sencillas e idénticas excepto por la columna de identificación. La estructura estará basada en la FakeTable creada en el artículo Millones de Datos Aleatorios en SQL Server.
Mismas tablas, diferentes identificadores.
CREATE TABLE [dbo].[FakeTable_with_Identity](
[RowId] [int] IDENTITY(1,1) NOT NULL PRIMARY KEY,
[Name] [varchar](16) NULL,
[MiddleName] [varchar](16) NULL,
[Office] [int] NULL,
[Gender] [smallint] NULL,
[DayOfBirth] [date] NULL,
[DescriptionText] [varchar](500) NULL
)
CREATE TABLE [dbo].[FakeTable_with_Uniqueidentifier](
[RowId] [uniqueidentifier] DEFAULT NEWID() NOT NULL PRIMARY KEY,
[Name] [varchar](16) NULL,
[MiddleName] [varchar](16) NULL,
[Office] [int] NULL,
[Gender] [smallint] NULL,
[DayOfBirth] [date] NULL,
[DescriptionText] [varchar](500) NULL
)Luego voy a insertar 10 registros a cada una de ellas. Mismos registros.
INSERT [dbo].[FakeTable_with_Identity]
([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES
('Monika', 'Tarah', 100, 5, CAST('2006-05-31' AS Date), 'Lorem ipsum dolor sit amet, consectetur adipiscing elit.'),
('Grethel', 'Emalia', 193, 4, CAST('1967-09-18' AS Date), 'Lorem ipsum dolor sit amet, consectetur adipiscing '),
('Kandace', 'Suellen', 180, 4, CAST('1980-01-01' AS Date), 'Lorem ipsum '),
('Becki', 'Kimberly', 100, 2, CAST('1973-01-04' AS Date), 'Lorem ipsum dolor sit amet, consecte'),
('Tonia', 'Stacey', 100, 4, CAST('2003-11-26' AS Date), 'Lorem ipsum dolor sit amet, co'),
('Paulette', 'Demeter', 134, 5, CAST('1974-01-20' AS Date), 'Lorem ipsum dolor sit amet, consectetur ad'),
('Olenka', 'Doretta', 100, 5, CAST('2009-04-11' AS Date), 'Lorem ipsum dolor sit am'),
('Marlane', 'Janaye', 100, 2, CAST('1961-10-24' AS Date), 'Lorem ipsum dolor si'),
('Shela', 'Fredi', 100, 5, CAST('1969-02-18' AS Date), 'Lorem ipsum dolor sit amet,'),
('Angela', 'Arluene', 200, 3, CAST('1987-11-03' AS Date), 'Lorem ipsu')
INSERT [dbo].[FakeTable_with_Uniqueidentifier]
([Name], [MiddleName], [Office], [Gender], [DayOfBirth], [DescriptionText]) VALUES
('Monika', 'Tarah', 100, 5, CAST('2006-05-31' AS Date), 'Lorem ipsum dolor sit amet, consectetur adipiscing elit.'),
('Grethel', 'Emalia', 193, 4, CAST('1967-09-18' AS Date), 'Lorem ipsum dolor sit amet, consectetur adipiscing '),
('Kandace', 'Suellen', 180, 4, CAST('1980-01-01' AS Date), 'Lorem ipsum '),
('Becki', 'Kimberly', 100, 2, CAST('1973-01-04' AS Date), 'Lorem ipsum dolor sit amet, consecte'),
('Tonia', 'Stacey', 100, 4, CAST('2003-11-26' AS Date), 'Lorem ipsum dolor sit amet, co'),
('Paulette', 'Demeter', 134, 5, CAST('1974-01-20' AS Date), 'Lorem ipsum dolor sit amet, consectetur ad'),
('Olenka', 'Doretta', 100, 5, CAST('2009-04-11' AS Date), 'Lorem ipsum dolor sit am'),
('Marlane', 'Janaye', 100, 2, CAST('1961-10-24' AS Date), 'Lorem ipsum dolor si'),
('Shela', 'Fredi', 100, 5, CAST('1969-02-18' AS Date), 'Lorem ipsum dolor sit amet,'),
('Angela', 'Arluene', 200, 3, CAST('1987-11-03' AS Date), 'Lorem ipsu')Ahora veamos qué sucede si ejecutamos una consulta completa a ambas tablas.
Vamos también a analizar su plan de ejecución.
SELECT *
FROM [dbo].[FakeTable_with_Identity]
SELECT *
FROM [dbo].[FakeTable_with_Uniqueidentifier]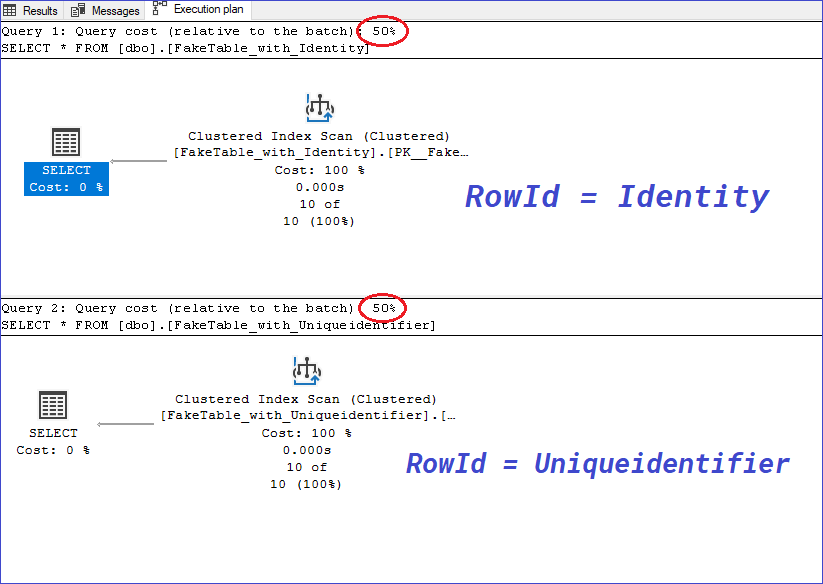
¿Qué te parece?
Son idénticos y con un costo de operación distribuido en partes iguales. Parece que ambos escenarios no tienen diferencia y que el esfuerzo es exactamente el mismo en una consulta de este estilo.
¿Qué pasa cuando trabajas con volúmenes más grandes? Mira la Segunda Parte de este artículo para conocer más detalles.
Related Posts

