
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Cantidad aproximada de filas en tabla de SQL Server
Cuando necesitas saber cuántos registros tiene una tabla que es muy grande, usualmente el COUNT que quieras usar se tome su tiempo en responderte. Pero, ¿qué tal si solo te bastara con saber la cantidad aproximada de filas para tener un estimado? Es así que nace una nueva función dentro de todo Lo Nuevo que trae SQL Server 2019.
Sobretodo cuando empiezas la analítica de datos, algunos de los valores útiles para este análisis suelen venir de la mano de las cantidades de filas, cantidades de valores únicos, promedios, medias, etc.
Vamos el lado de la necesidad de valores únicos en una columna de una tabla.
¿Qué hacemos?
Posiblemente la solución más fácil sea un SELECT COUNT DISTINCT (columna).
Pero, ¿has visto cómo es el performance de algo así?
Qué tal si lo vemos en este ejemplo.
SELECT COUNT(DISTINCT([WWI Order ID]))
FROM Fact.OrderHistoryExtended
OPTION (USE HINT('DISALLOW_BATCH_MODE'), RECOMPILE);
(La última línea solo la colocamos para simular que el query no utilizará el BATCH MODE y se ejecutará como ROW MODE)

He remarcado el Hash Match ya que es un operador que muy a menudo está presente en consultas con COUNT, y como en este caso, puede también presentarse las alertas del spill on tempdb.
Pero lo que más quiero que te llame la atención es la cantidad de registros que devuelve este operador.
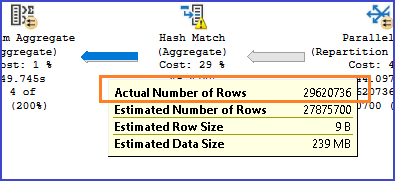
Usando APPROX_COUNT_DISTINCT
Veamos cómo puedes cambiar la cara a esta consulta.
Si este es uno de los casos en los que no necesitas un valor exacto en el conteo de datos, es posible obtener una cantidad aproximada de filas utilizando esta nueva función.
SELECT APPROX_COUNT_DISTINCT([WWI Order ID])
FROM Fact.OrderHistoryExtended
¿Y cómo queda el plan de ejecución?
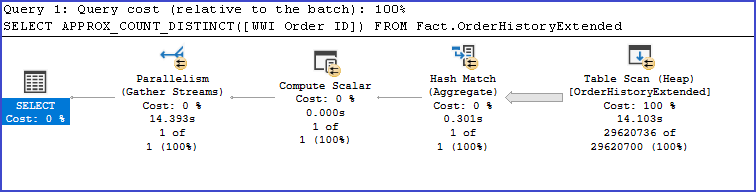
Y lo mejor…optimizamos el Hash Match. Puedes ver que ya no se devuelven todos esos 29 millones de registros.
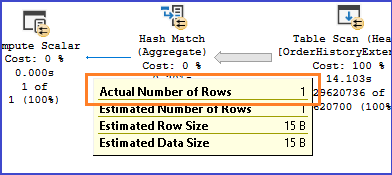
No sé tú, pero yo estoy asombradísimo con esta alternativa.
Entonces, ¿dónde está lo malo?
No te olvides el nombre de esta función. Exacto, esto solo nos da un dato aproximado.
Si bien hemos mejorado muchísimo el rendimiento de la consulta en este ejemplo (y algo que no viste, en mi caso se redujo el tiempo de ejecución en un 70%), aplicando la función APPROX_COUNT_DISTINCT solo tendremos valores estimados de resultados.
De todas maneras, no creas que el resultado es tal alejado de la realidad. Según las consideraciones en la documentación oficial, se sabe que esta función tiene solamente un 2% de error con un 97% de probabilidad. Bastante bien.
¿Por qué obtener una cantidad aproximada de filas?
Como ya lo habíamos mencionado, esta es una alternativa para cuando podemos tolerar esos porcentajes de error.
Usualmente en Big Data podemos tener ciertos márgenes cuando realizamos análisis.
APPROX_COUNT_DISTINCT utilizará bastante menos memoria que un COUNT DISTINCT.
Su uso será más beneficioso cuando estamos hablando de unos cuantos millones de registros.
Related Posts

