
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Cómo generar números aleatorios en SQL Server
Cuando requieres insertar números diferentes en tus tablas, la función random viene a tu cabeza inmediatamente. Lo que observamos en las resultados de las consultas a veces nos causa dudas sobre su uso correcto, por eso es importante comprender cómo se generan estos números aleatorios en SQL Server.
Función RAND()
Según la documentación oficial de Microsoft acerca de rand(), su ejecución supone la devolución de un valor float entre 0 y 1. Esto quiere decir que podemos simular siempre un valor randómico al azar.
La sintaxis nos dice que debemos ejecutar:
RAND( [seed] )
Donde el valor de «seed» representa a una semilla. Este valor no representa un máximo ni un límite del número aleatorio como a veces se piensa. Lo que debe estar claro que si ejecutamos la función RAND con un valor de semilla, siempre obtendremos el mismo número aleatorio.
Por ejemplo, veamos cuatro llamadas posicionando a la misma semilla en diferentes lugares.
SELECT RAND(100), RAND(), RAND(), RAND()
GO
SELECT RAND(), RAND(100), RAND(), RAND()
GO
SELECT RAND(), RAND(), RAND(100), RAND()
GO
SELECT RAND(), RAND(), RAND(), RAND(100)
GO
Podemos ver el resultado tal cual menciona esta teoría.
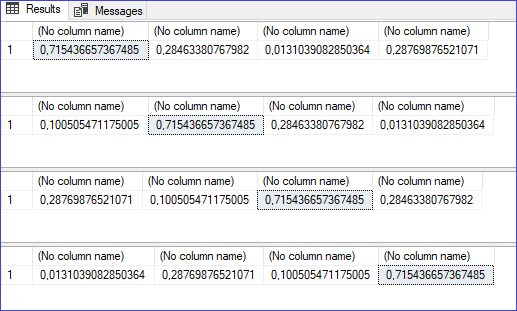
Quiero que notes que los resultados sombreados tienen exactamente el mismo valor. Es justamente lo que causa la asignación de un valor semilla.
Es más, los siguientes resultados de RAND que no tienen semilla dependen del RAND que sí tenía semilla. Puedes notar que los siguientes resultados a los sombreados también son idénticos.
¿Entonces cómo generaría siempre diferentes valores aleatorios?
No utilizando una semilla, claro está. Veamos el mismo ejemplo y su resultado.
SELECT RAND(), RAND(), RAND(), RAND()
GO
SELECT RAND(), RAND(), RAND(), RAND()
GO
SELECT RAND(), RAND(), RAND(), RAND()
GO
SELECT RAND(), RAND(), RAND(), RAND()
GO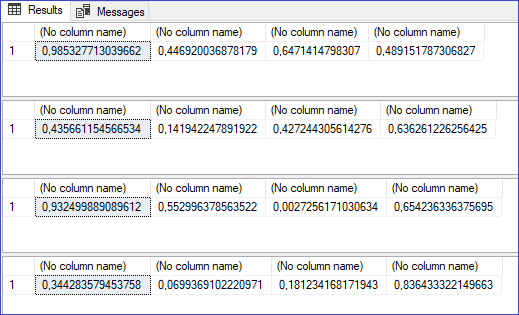
¿Lo notaste? Todos los valores diferentes porque no hay una dependencia de una semilla en ningún lugar.
Si utilizamos RAND en una consulta
Un ejemplo sencillo en el que a una consulta adicionamos una columna con la intención de generar valores aleatorios.
SELECT name, create_date, modify_date, RAND() AS RandomNum
FROM sys.tables
ORDER BY 1
El resultado es el siguiente.
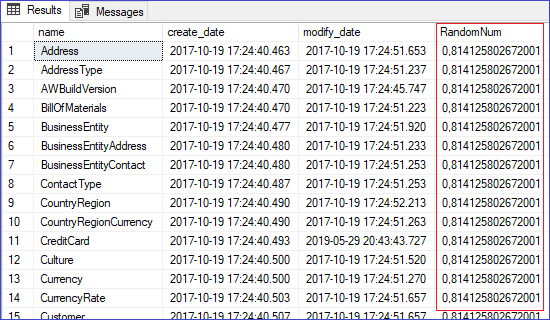
Donde claramente vemos el mismo valor aleatorio en cada registro. Pasa lo mismo cuando hacemos un INSERT o un UPDATE, ¿verdad?
Cuando necesitas números aleatorios en SQL Server
Y si los necesitas en cada registro, debemos buscar otro camino.
Podemos hacer una combinación de las funciones CHECKSUM() y NEWID(). Veamos el ejemplo.
SELECT name, create_date, modify_date, RAND(CHECKSUM(NEWID())) AS RandomNum
FROM sys.tables
ORDER BY 1
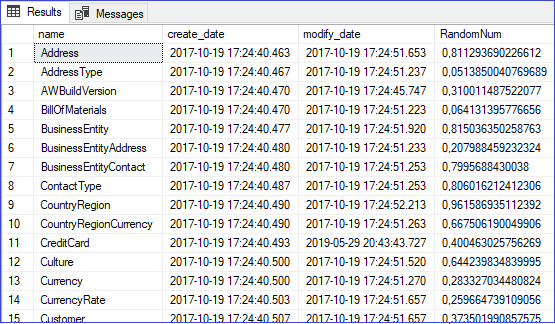
Pues ahora sí tenemos el resultado que queríamos.
¿Qué nos queda?
Si queremos un número aleatorio con un número máximo, podemos multiplicar el número randómico que ya tenemos por ese valor. Si queremos un número enterno pues hacerle un CAST o CONVERT.
También puedes ver Cómo generar fechas Aleatorias en SQL Server y también un ejemplo más completo de cómo generar Millones de datos Aleatorios para tus pruebas.
Related Posts

