
Para desplegar nuestras bases de datos en la nube tenemos diferentes alternativas. Esto no es…
Importar a Azure SQL Database desde Azure Storage
Desde siempre ha existido la necesidad de llevarnos la información de archivos planos hacia una base de datos. Qué mejor forma de aprovechar Azure Data Factory para importar a Azure SQL Database desde la información guardada en un Azure Storage.
Antes de empezar, ¿ya tienes Azure Data Factory listo? Si no lo has usado puedes ir primero al artículo Cómo Configurar Azure Data Factory para comprender y hacer estos primeros pasos.
Ahora a crear un Flujo
Si no tienes mayor transformación que hacer en la copia de datos, puedes ir por el camino más rápido. Selecciona la opción de Copy Data desde el portal de Azure Data Factory.
Inmediatamente debes empezar con identificar a la tarea. Esta puede ser también agendada, aunque en esta ocasión, no entraré a mayor detalle de ello.
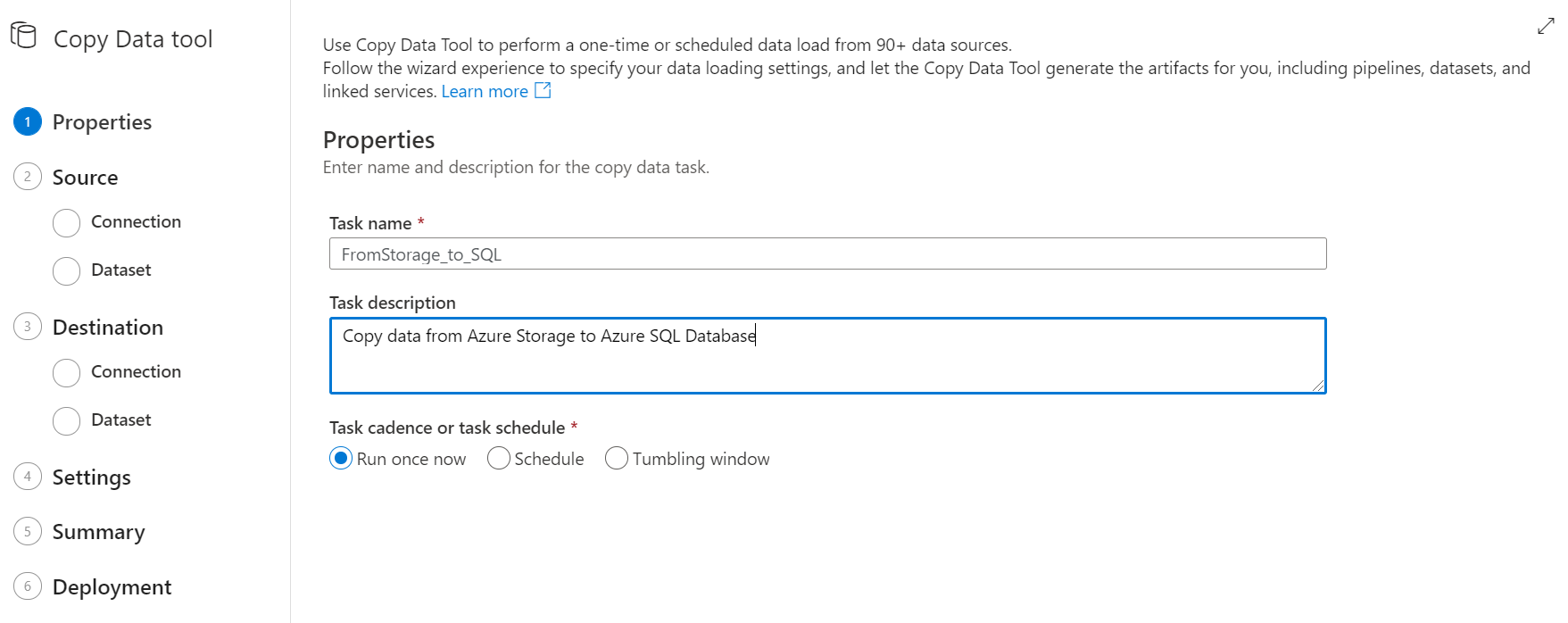
A continuación deberás seleccionar la fuente de dónde quieres obtener la información. Este proceso lo explicamos en el artículo previo denominado Exportar Tablas de Azure SQL a Azure Storage. Ahí puedes ver cómo se han creado las conexiones.
Aquí verás que podemos aprovechar esas conexiones creadas para seleccionar el origen de datos.
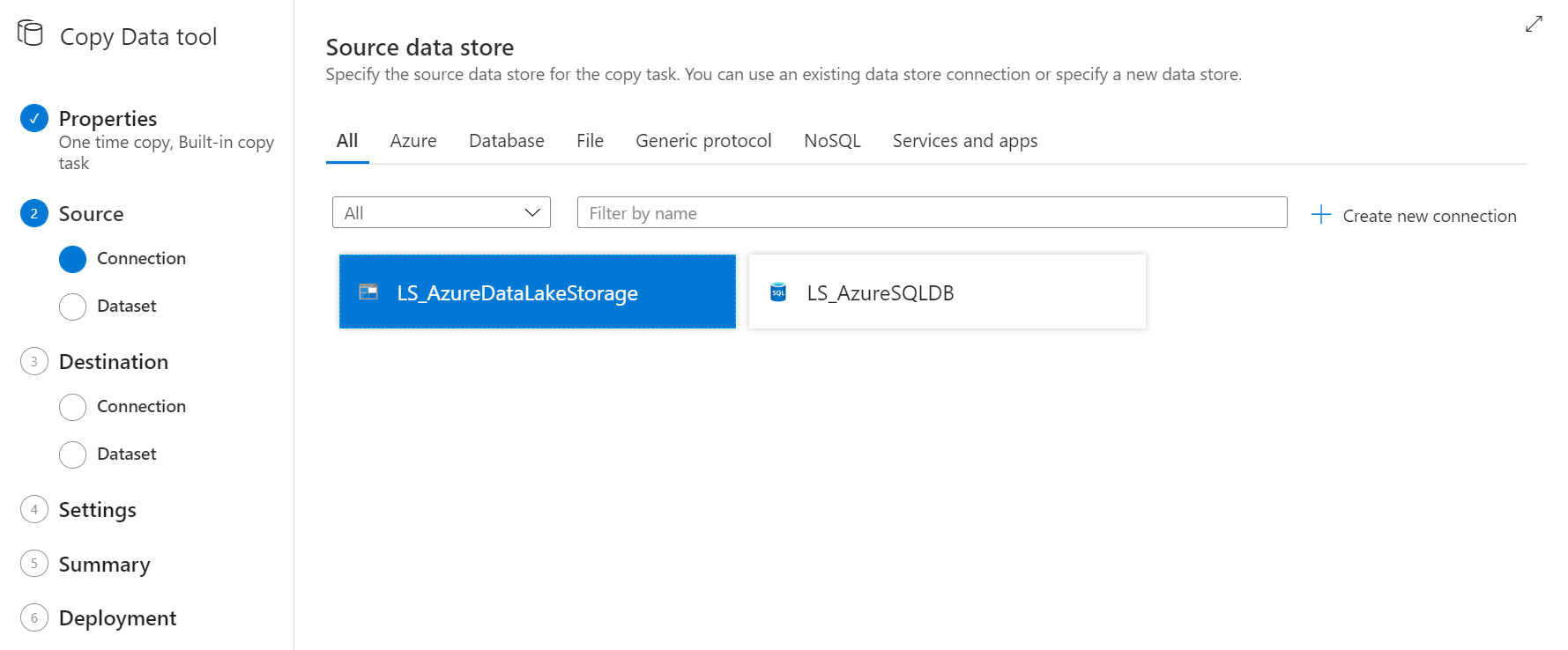
Seleccionas el archivo que va a ser el origen en la copia de datos.
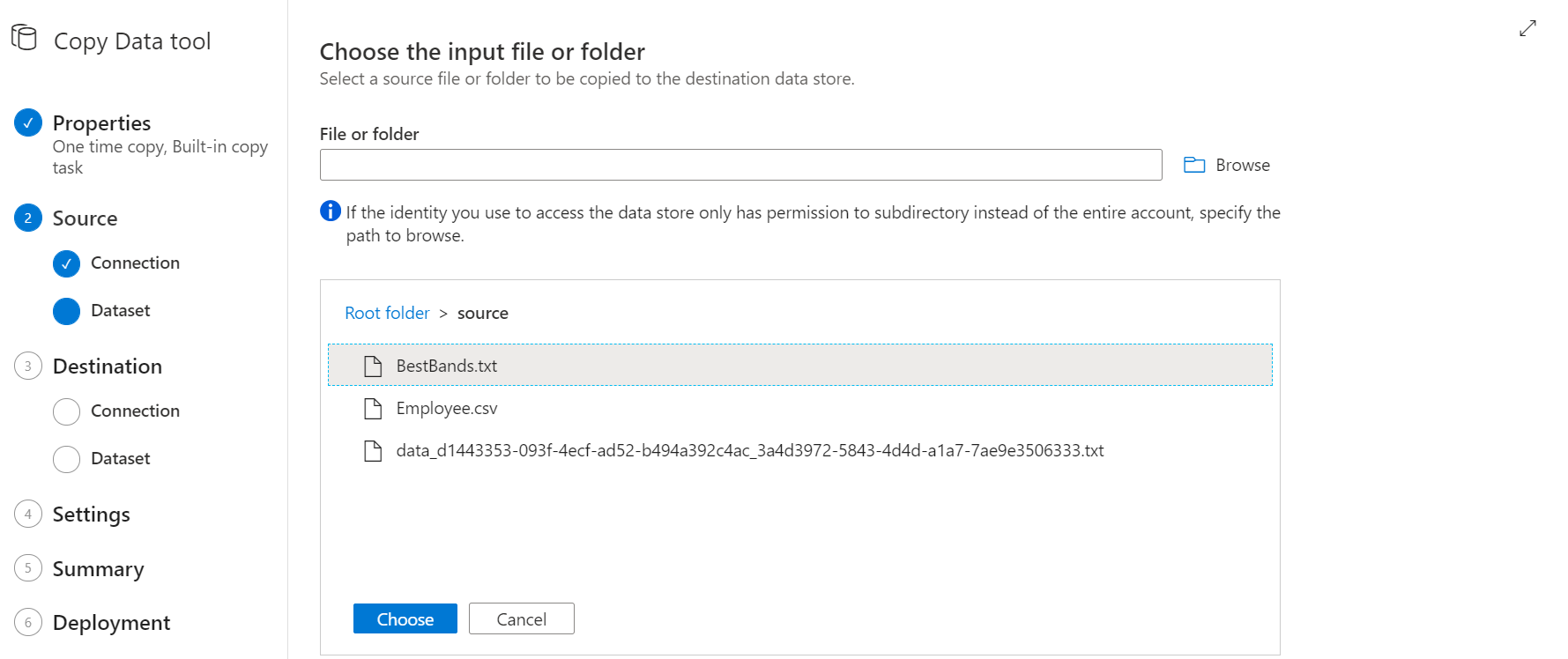
Luego de seleccionar el archivo, puedes ver que hay configuraciones adicionales para copias recursivas, máximo número de conecciones recurrentes y otros que se comentarán en un próximo artículo. Por ahora si solo nos limitamos a la copia de datos, puedes saltar este paso sin cambiar nada.
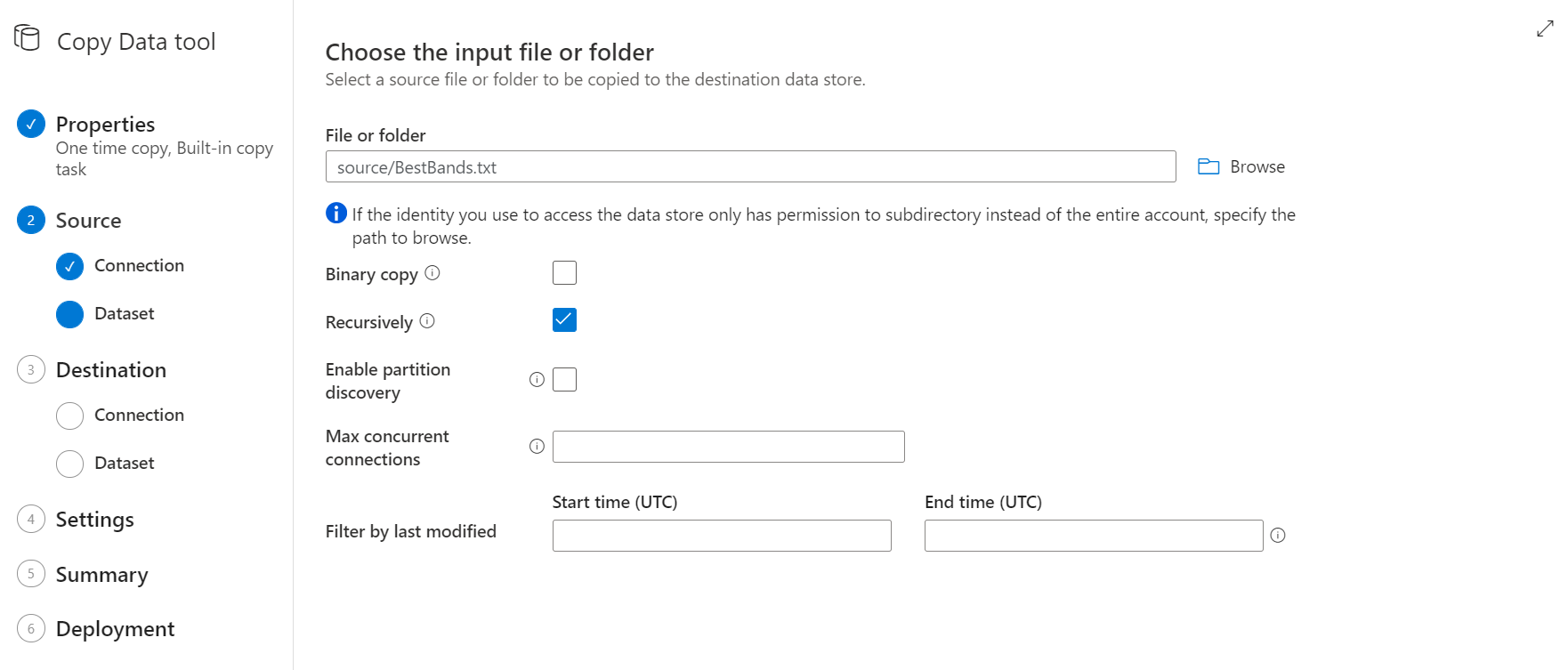
Ahora es momento de algunas configuraciones particulares del texto que estás importando.
- Formato del archivo: txt, parquet, json, avro u otro disponible
- Separador de columnas: pipe, coma, etc
- En general, todo aquello que me permita darle un formato al archivo de entrada
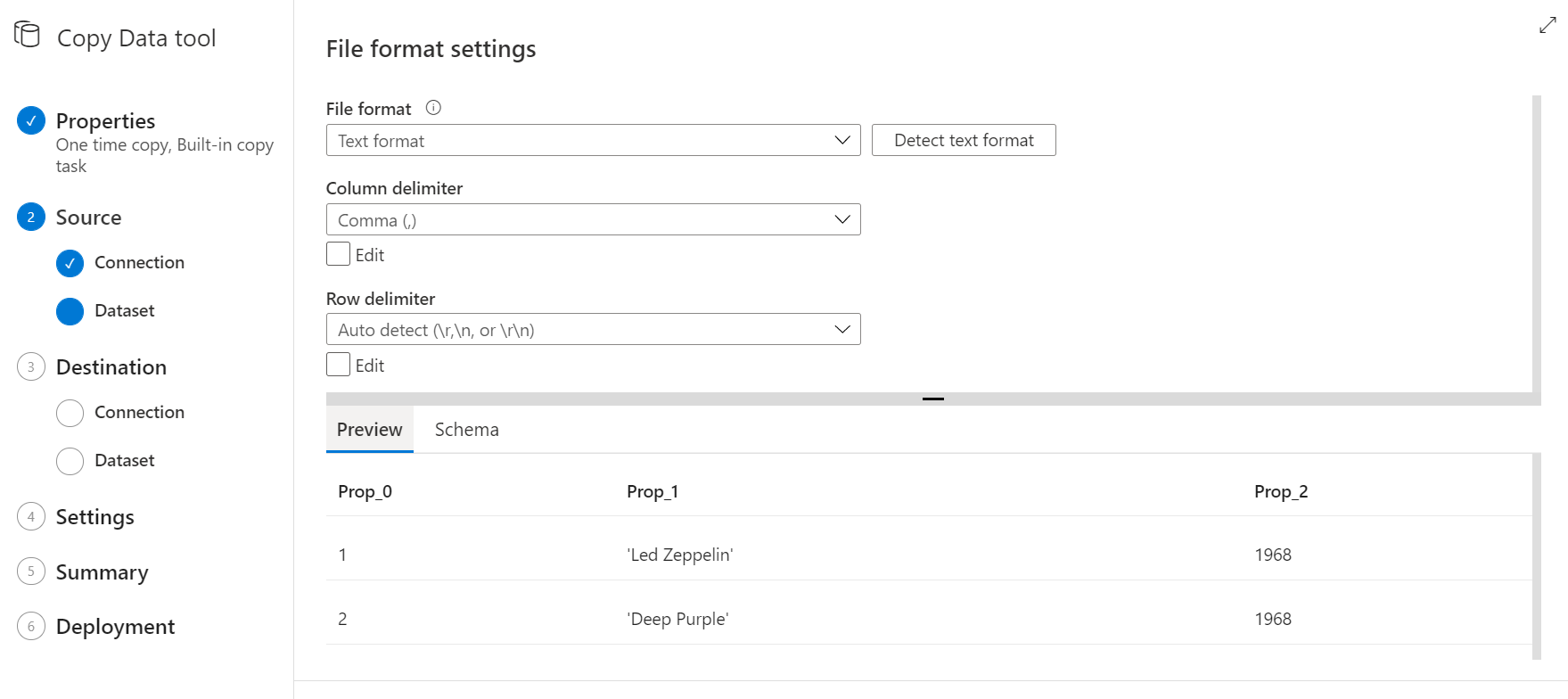
Después pasarás a la selección del destino. Ya tenemos previamente una conexión hacia una base Azure SQL.
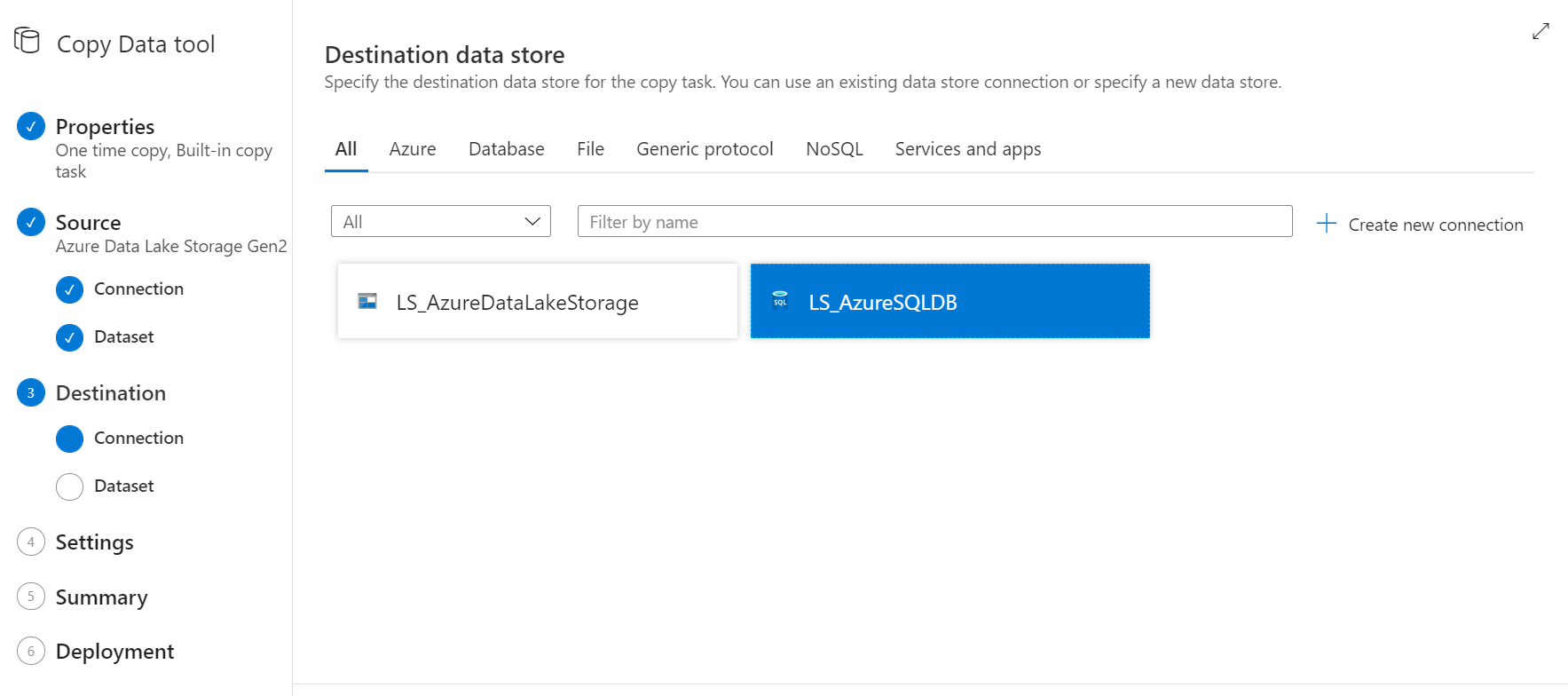
Habiendo seleccionado la base de datos destino, quedan dos caminos para continuar. ¿Quieres que se cree una tabla en Azure SQL o quieres utilizar una que ya existe?
En este ejemplo voy a crear una tabla nueva.
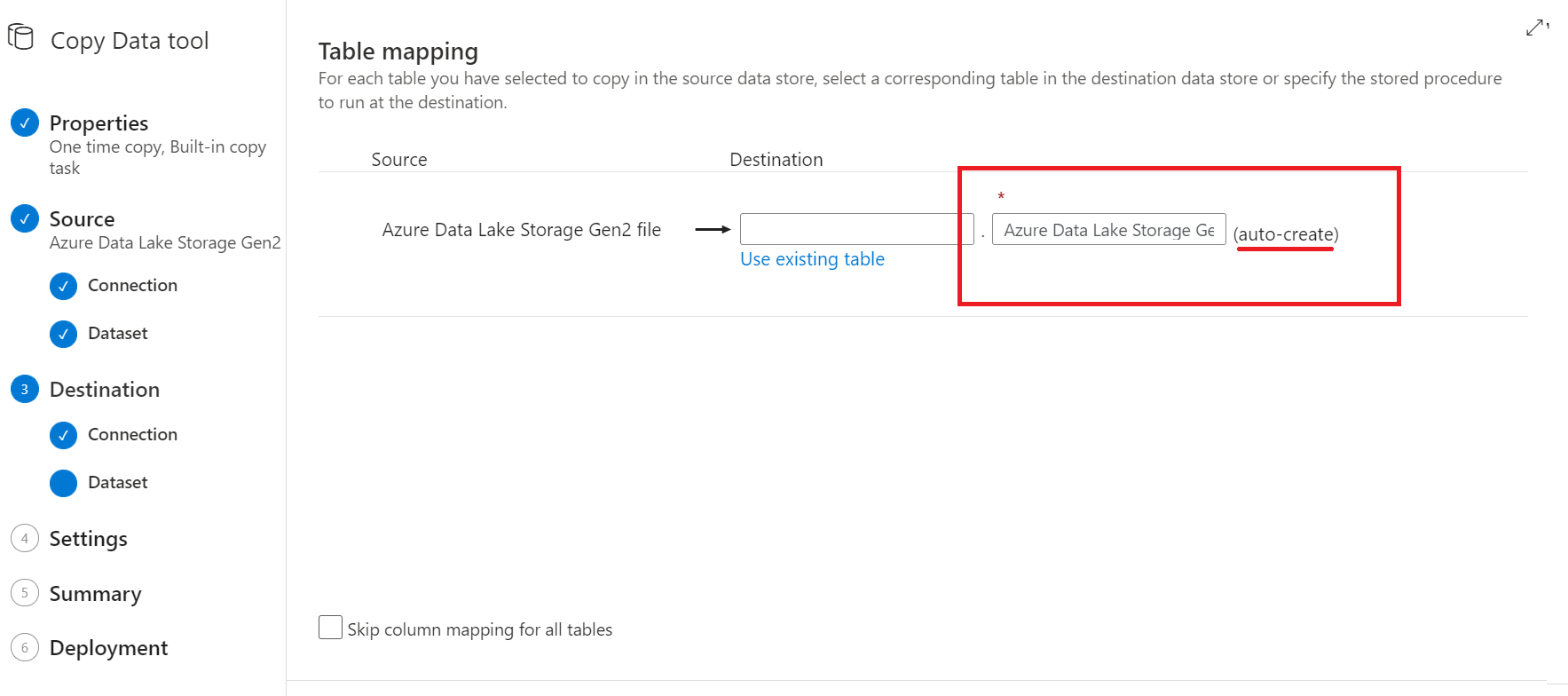
(Claro, idealmente deberías colocar un nombre más interesante al destino)
Luego te pedirán definir los ‘mappings’ para las relaciones de columna. En este caso dejé todo por defecto así que tampoco tendrás nombres de columnas.
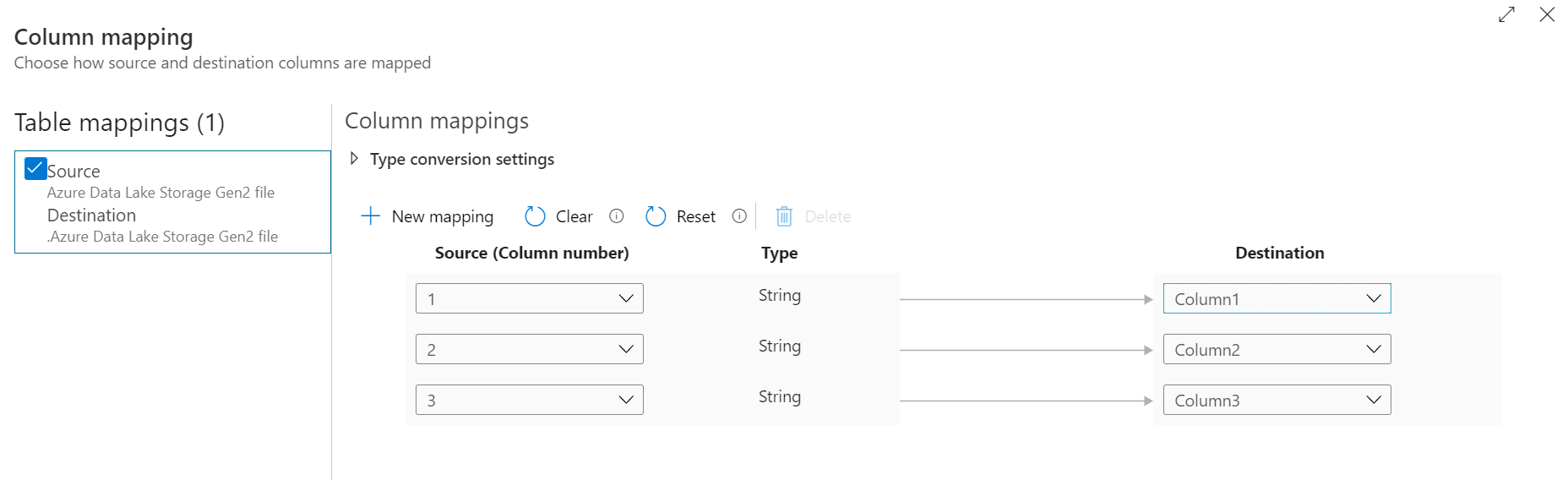
Si has pensado que no se ve bien que estos datos vayan a una tabla sin nombres de columnas, estás en lo correcto. Mejor sería tener una tabla de destino con los nombres ya establecidos o, tener el archivo plano con los nombres de las columnas.
Bueno…continuemos.
El siguiente paso te muestra las configuraciones generales del proceso de copia. Verás la opción de verificar la consistencia de la copia, añadir tolerancia a fallos, habilitar logs y otros.
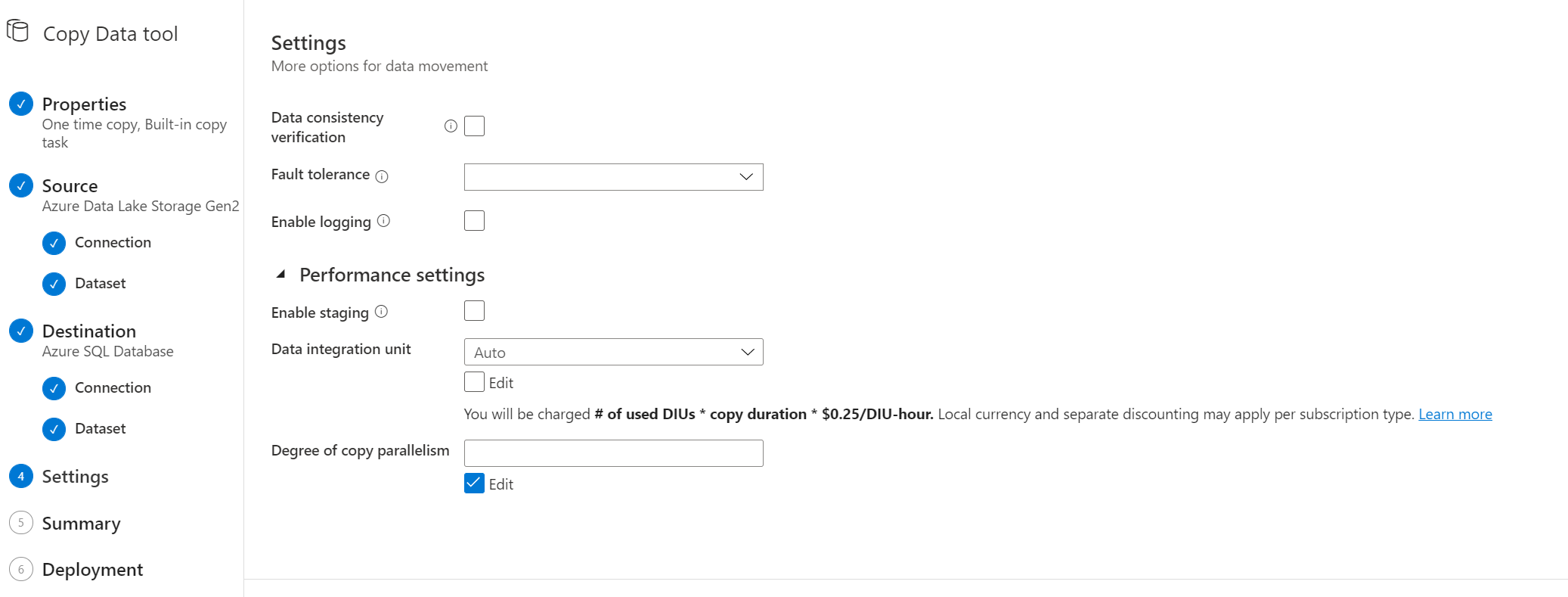
Uno de los más relevantes considero que es el que dice «Degree of copy parallelism». Con este valor puedes configurar el asignar mayor procesamiento para la copia para así optimizar el proceso.
Paso final. Verifica que todo esté correctamente configurado.
Al final para hacer el deploy por completo, al darle click al botón de Next verás cómo se crean los datasets, el pipeline y luego se ejecuta todo el flujo.
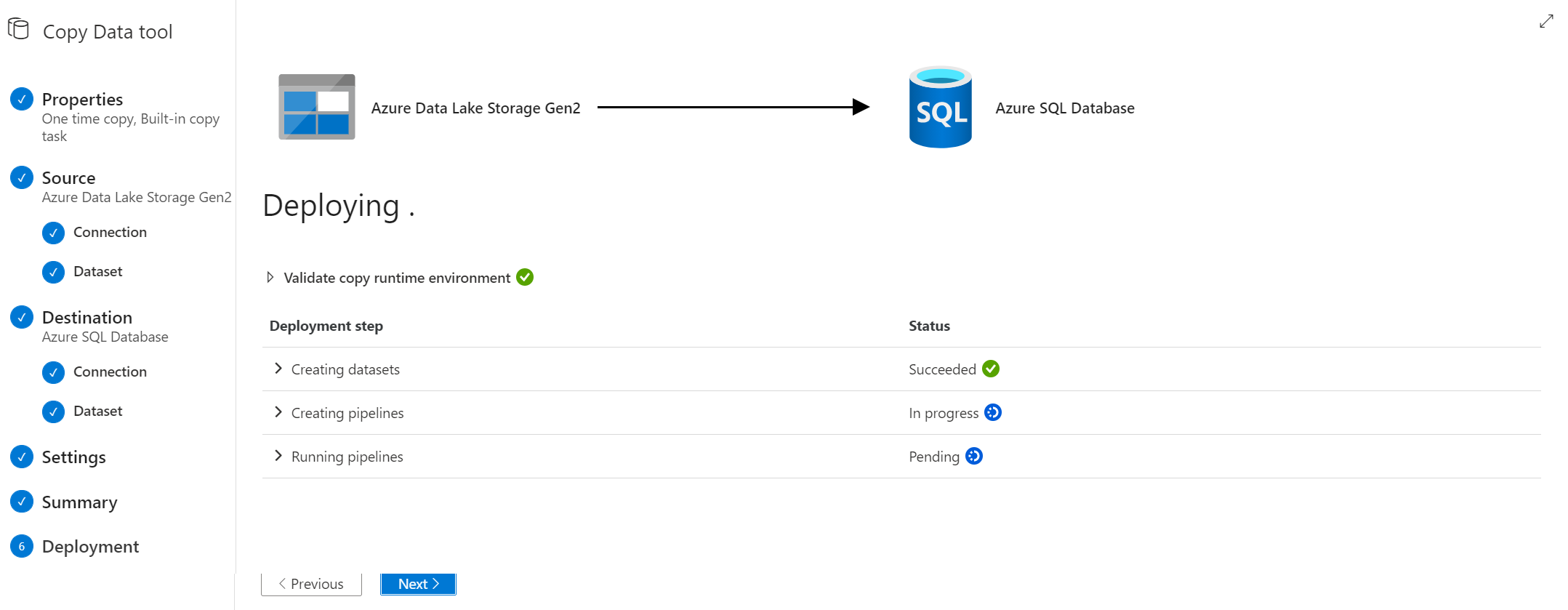
Resultado al importar a Azure SQL Database desde el Storage
Simplemente conéctate a tu base de datos destino y haz una consulta sobre la tabla que has creado. Si no le has dado un nombre como en este ejemplo, pues el resultado es evidente.
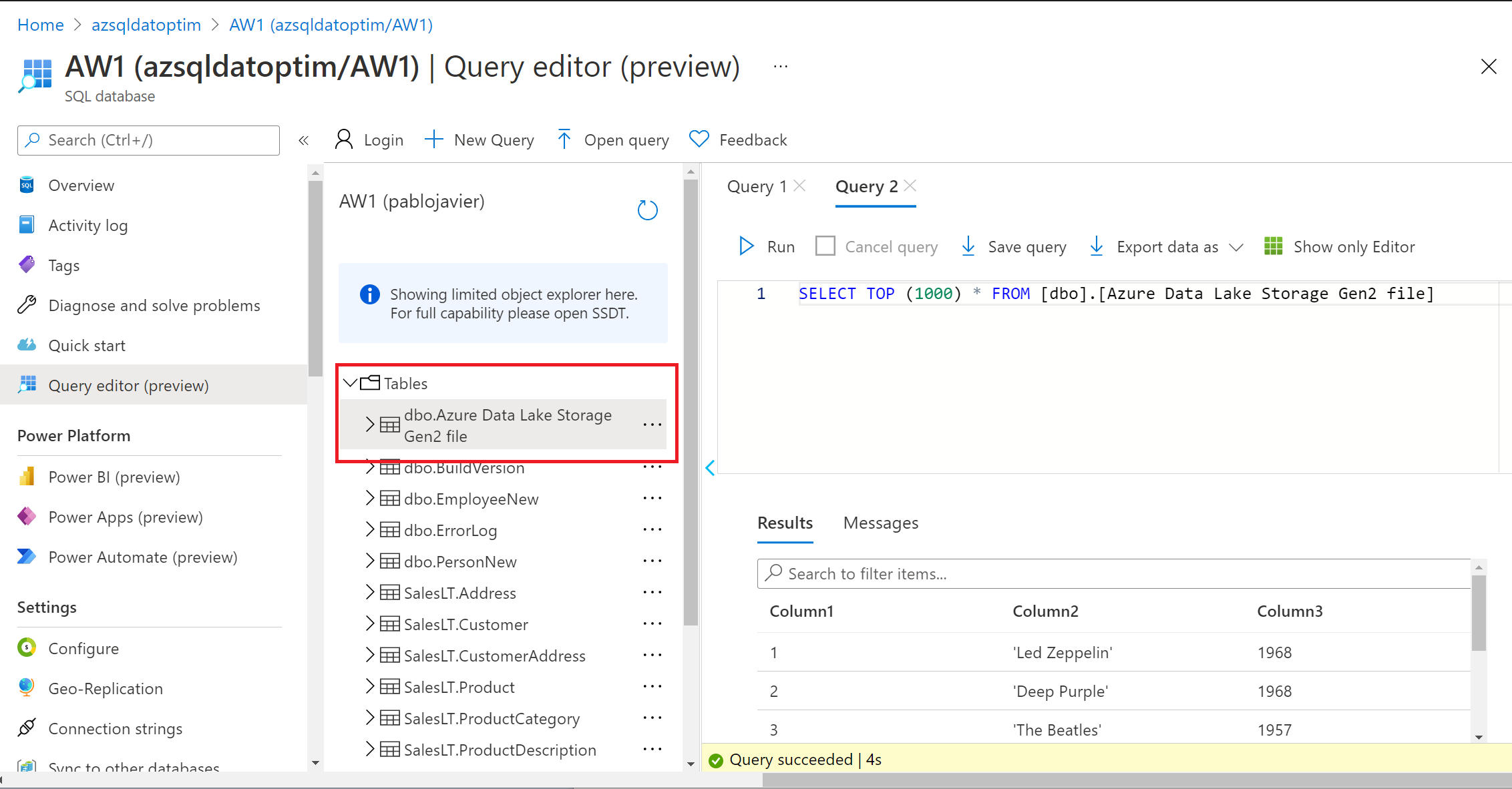
Puedes estar seguro que los datos ahora se encuentran en la base de datos tal y como lo has configurado.