
Lo primero para empezar el trabajo con SQL Server es preparar el ambiente. La instalación…
Problemas al consultar millones de registros en SQL Server
Estaría de más que te pidamos más detalles de los problemas de los que estás hablando. Si lo primero de lo que hablamos es de consultar millones de registros en SQL Server y la conversación empieza con «Problemas», muy probablemente quieras hablar de «Lentitud».
¿Es verdad que mientras más registros tienen nuestras tablas, más lentos se ponen los programas? Veremos de qué se trata todo esto.
¿Cúando una tabla es «Grande»?
Hablar de «millones» ya parece un símbolo de magnitud considerable. El punto aquí es que no dependemos de este número.
Una tabla puede tener un volumen mayor dependiendo de diferentes factores como:
- Tipos de datos
- Cantidad de columnas
- Cantidad de índices
- Cantidad de registros
- Fill Factor
Así que olvida que el tamaño depende de la cantidad de filas en una tabla.
Primero debes entender esta teoría
Utiliza la tabla FakeTable que creamos en el artículo Millones de datos aleatorios en SQL Server.
Basados en esta tabla crearemos unas adicionales pero cargando los mismos datos que ya tiene. Inicia creando las tablas.
-- We need FakeTable created already
-- CREATE TABLE FakeTable2
-- We change some data types from FakeTable
CREATE TABLE FakeTable2 (
RowId BIGINT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(16),
MiddleName NVARCHAR(16),
Office INT,
Gender INT,
DayOfBirth DATE,
DescriptionText NVARCHAR(500)
)
-- CREATE TABLE FakeTable3
-- We add some indexes from FakeTable2
CREATE TABLE FakeTable3 (
RowId BIGINT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(16),
MiddleName NVARCHAR(16),
Office INT,
Gender INT,
DayOfBirth DATE,
DescriptionText NVARCHAR(500)
)
CREATE INDEX IX_FT3_1 ON FakeTable3 (Name)
CREATE INDEX IX_FT3_2 ON FakeTable3 (MiddleName)
CREATE INDEX IX_FT3_3 ON FakeTable3 (Gender) INCLUDE (Office)
CREATE INDEX IX_FT3_4 ON FakeTable3 (Office,DayOfBirth) INCLUDE(Gender)
-- CREATE TABLE FakeTable3
-- We add FILL FACTOR TO indexes from FakeTable3
CREATE TABLE FakeTable4 (
RowId BIGINT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(16),
MiddleName NVARCHAR(16),
Office INT,
Gender INT,
DayOfBirth DATE,
DescriptionText NVARCHAR(500)
)
CREATE INDEX IX_FT4_1 ON FakeTable4 (Name) WITH (FILLFACTOR = 80)
CREATE INDEX IX_FT4_2 ON FakeTable4 (MiddleName) WITH (FILLFACTOR = 80)
CREATE INDEX IX_FT4_3 ON FakeTable4 (Gender) INCLUDE (Office) WITH (FILLFACTOR = 80)
CREATE INDEX IX_FT4_4 ON FakeTable4 (Office,DayOfBirth) INCLUDE(Gender) WITH (FILLFACTOR = 80)
ALTER INDEX IX_FT4_1 ON dbo.FakeTable4 REBUILD
ALTER INDEX IX_FT4_2 ON dbo.FakeTable4 REBUILD
ALTER INDEX IX_FT4_3 ON dbo.FakeTable4 REBUILD
ALTER INDEX IX_FT4_4 ON dbo.FakeTable4 REBUILD¡Bien! Ya están creadas las 4 tablas que como puedes ver tienen algunas variaciones de las que hemos mencionado como factores que determinan el volumen de una tabla.
Ahora vamos a insertar los mismos registros que la tabla FakeTable que creamos en el artículo mencionado más arriba.
-- Repeat with FakeTable3, FakeTable4
INSERT INTO FakeTable2 (Name, MiddleName, Office, Gender, DayOfBirth, DescriptionText)
SELECT
Name,
MiddleName,
Office,
Gender,
DayOfBirth,
DescriptionText
FROM FakeTableNo te olvides que estamos trabajando con EXACTAMENTE los mismos datos y las mismas cantidades de registros en todas las tablas.
Solamente para adicionar un poco de emoción, crearemos una quinta tabla, más sencilla y solo con dos columnas. La cargamos también con datos; menos de la mitad de la primera tabla.
-- CREATE TABLE FakeTable5
-- Just 2 columns: Id and Description
CREATE TABLE FakeTable5(
RowId BIGINT IDENTITY(1,1) PRIMARY KEY,
DescriptionText NCHAR(4000)
)
INSERT INTO FakeTable5 (DescriptionText)
SELECT 'SomeText'
GO 265000
Ahora analiza los resultados
Vamos a sacar un reporte de tablas y tamaños en la base de datos. Puedes ayudarte ejecutando el procedimiento sp_ReportUserDBTables. Si no lo tienes, visita la publicación Genera un Reporte de Tablas de SQL Server.
EXEC sp_ReportUserDBTables
Vamos a enfocarnos en las columnas señaladas. Mira cómo quedan las proporciones en este ejercicio.
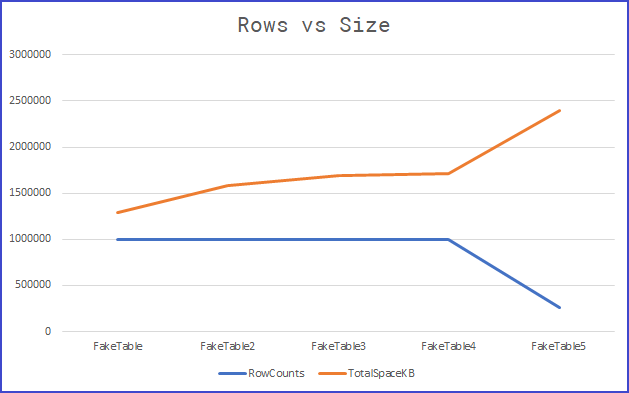
- En las primeras 4 tablas mantenemos la cantidad de registros
- En las primeras 4 tablas existen diferentes tamaños requeridos
- La 5ta tabla tiene muchos menos registros
- La 5ta tabla es mucho más grande que las primeras 4
Entonces ¿cómo consultar millones de registros en SQL Server?
Primero que nada, olvídate que la cantidad de filas es una dificultad.
Uno de los factores importantes que determina la dificultad del procesamiento de una consulta, es la cantidad de páginas que ella va a leer.
Claramente podemos ver que mientras más almacenamiento requiere una tabla, mayor la cantidad de páginas que van a ser leídas.
El ejemplo te lo muestra de una manera muy intuitiva. Podemos consultar menor cantidad de registros (Tabla5) pero tener mayor espacio en disco ocupado. O tener la misma información (Tablas1-4) con diferentes necesidades de espacio.
Optimizar para consultar millones de registros
Millones o no, siempre hay alternativas. Para empezar, puedes ver este artículo sobre Cómo hacer consultas más rápidas en SQL Server.
La cantidad de páginas que vas a leer es muy importante, por eso, revisa Cómo medir la lectura en SQL Server.
Cuando consigas reducir la cantidad de lectura, a través de índices u optimización de estructuras y consultas, verás cómo vas optimizando las operaciones en tu base de datos.
Related Posts

